学习Node.js:解析express body-parser中间件源码
本文我们通过实现一个简易的body-parser功能,然后去阅读body-parser中间件源码来学习Nodejs
body-parser是什么
body-parser是一个经常会用到的express中间件,可以解析传入的请求体,会吧解析之后的属性添加到req.body 上面,主要用于解析Content-Type为json、urlencoded、octet-stream、text/plain格式的请求体,我们重点来关注一下前两种类型
使用body-parser处理json类型的请求体
const express = require('express');const bodyParser = require('body-parser');
const app = express();
// 使用 bodyParser.json 中间件来处理 JSON 请求体数据app.use(bodyParser.json());
app.post('/api/data', (req, res) => { // 获取解析后的 JSON 数据 const jsonData = req.body; console.log(jsonData) res.send({ message: 'JSON 数据已接收并处理' });});
app.listen(3000, () => { console.log(`Server is running on port 3000`);});解析json格式的请求只需要使用bodyParser.json()中间件就行,然后解析之后的json数据就会被添加在req.body之上
可以使用curl来请求上面这个服务:
curl -X POST -H "Content-Type: application/json" -d '{"age": 18}' [http://localhost:3000/api/data](http://localhost:3000/api/data)
打印的结果如下:

使用body-parser处理urlencoded类型的请求体
上面的代码只需要很小的改动:
app.use(bodyParser.urlencoded({ extended: false }));
app.post('/api/data', (req, res) => { // 获取解析后的 application/x-www-form-urlencoded 数据 const data = req.body; console.log(data) res.send({ message: '数据已接收并处理' });});继续可以使用curl来请求上面这个服务:
curl -X POST -d "name=zhangsan&age=18" [http://localhost:3000/api/data](http://localhost:3000/api/data)
结果如下:

使用Nodejs实现body-parser
在熟悉了body-parser基础用法之后,我们来自己实现一个简易的方法来处理json和urlencoded
起一个nodejs服务器
const http = require("http")
// 创建一个 HTTP 服务器const server = http.createServer((req, res) => {// 1 const contentType = req.headers["content-type"] console.log("contentType :>> ", contentType) res.end("hello world")})
const port = 3000server.listen(port, () => { console.log(`Server is running on http://localhost:${port}/`)})1,使用http.createServer就可以起一个服务器,req和res分别是请求和响应对象,然后我们打印出请求的conten-type
我们首先需要知道json和urlencoded请求对应的content-type,使用curl请求这个服务器可以得到:

处理json格式请求
const server = http.createServer((req, res) => { const contentType = req.headers["content-type"] if (contentType === "application/json") { let buffers = [] req.on('data', function (chunk) { // 1 buffers.push(chunk) })
req.on('end', function () { // 2 buffers = Buffer.concat(buffers) // 3 buffers = buffers.toString('utf-8') // 4 console.log('buffers :', buffers)
req.body = JSON.parse(buffers); // 5 console.log('req.body :', req.body) res.end("parse json") });
} else { res.end("hello world") }})1,监听请求对象 req 的 'data' ****事件。因为req对象继承了Node内置的EventEmitter模块,所以req可以监听很多事件
当客户端发送数据到服务器时,数据会以小块(chunk)的形式逐步传输,chunk的默认类型是Buffer,每次传输一个小块数据时,会触发一次 **'**data**'** 事件。然后吧chunk放在buffers数组中
2,监听req的end事件,end 事件是在可读流(如HTTP请求)的数据读取完毕时触发的事件。
3,Buffer.concat方法会返回新的 Buffer,它会吧 buffers 中的所有 Buffer 实例连接在一起
4,吧buffers数组转换成utf-8格式的字符串
5,使用JSON.parse吧字符串转成对象
使用curl请求这个服务器:
curl -X POST -d "key1=value1&key2=value2" [http://localhost:3000](http://localhost:3000/)
可以看到日志如下:

处理urlencoded格式请求
const querystring = require("querystring");if (contentType === "application/json") { ... } else if(contentType === "application/x-www-form-urlencoded") { let buffers = [] req.on('data', function (chunk) { buffers.push(chunk) })
req.on('end', function () { buffers = Buffer.concat(buffers) buffers = buffers.toString('utf-8') console.log('buffers :', buffers)
**req.body = querystring.parse(buffers); // 1** console.log('req.body :', req.body) res.end("parse json") }); } else{ ... }处理urlencoded和json格式只有注释1的代码有区别
1,querystring是Nodejs内置用于处理字符串的模块,使用querystring模块吧字符串转换成js对象,比如:key1=value1&key2=value2 会被转换成 { key1: ‘value1’, key2: ‘value2’}
使用curl请求这个服务器:
curl -X POST -d "key1=value1&key2=value2" [http://localhost:3000](http://localhost:3000/)
可以看到日志如下:

提取重复的代码
可以看到处理json和urlencoded格式代码有很多重复的代码,我们吧相似的地方封装一下
提取后的函数如下:
function handleRawStream(stream, callback) { const buffers = [] stream.on('data', function(chunk) { buffers.push(chunk) })
stream.on('end', function() { callback(Buffer.concat(buffers)); });}然后对之前的代码进行重构
if (contentType === "application/json") { handleRawStream(req, (buffer) => { const data = buffer.toString('utf-8') req.body = JSON.parse(data) console.log('req.body :', req.body); res.end("parse json") }) } else if (contentType === "application/x-www-form-urlencoded") { handleRawStream(req, (buffer) => { const data = buffer.toString('utf-8') req.body = querystring.parse(data) console.log('req.body :', req.body) res.end("parse json") })使用curl重新请求,仍然可以成功响应

接下来我们一起看一下body-parser是如何解析这几种请求格式的~
body-parser源码阅读
首先确定版本,我选择的是body-parser v1.20.2这个版本,这是1.x中的最后一个版本,地址:https://github.com/expressjs/body-parser/tree/1.20.2
目录结构
body-parser目录结构如下:
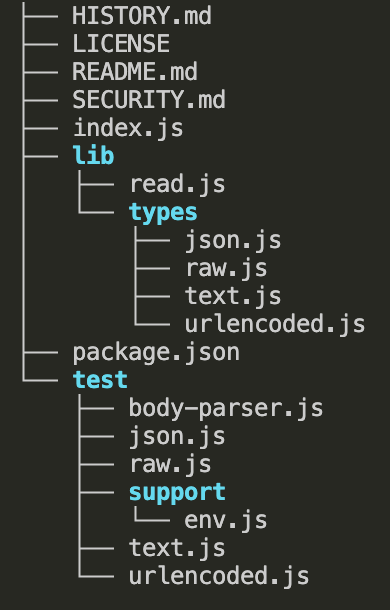
index.js主要作用就是引入lib目录下面的文件,然后导出去
lib目录是核心代码,其中types目录下的文件作用如下:
json.js用于解析application/json格式的请求体
urlencoded.js用于解析application/x-www-form-urlencoded格式的请求体
text.js用于解析text/plain格式的请求体
raw.js用于解析application/octet-stream格式的请求体
read.js被json.js、urlencoded.js等文件依赖,主要作用是读取 HTTP 请求的主体,将其解析并存储在 req.body 中,以便后续中间件可以访问请求主体的数据。
test目录是测试相关的代码
index.js阅读
index.js是 body-parser 模块的入口文件,主要用于导出各种请求主体解析器
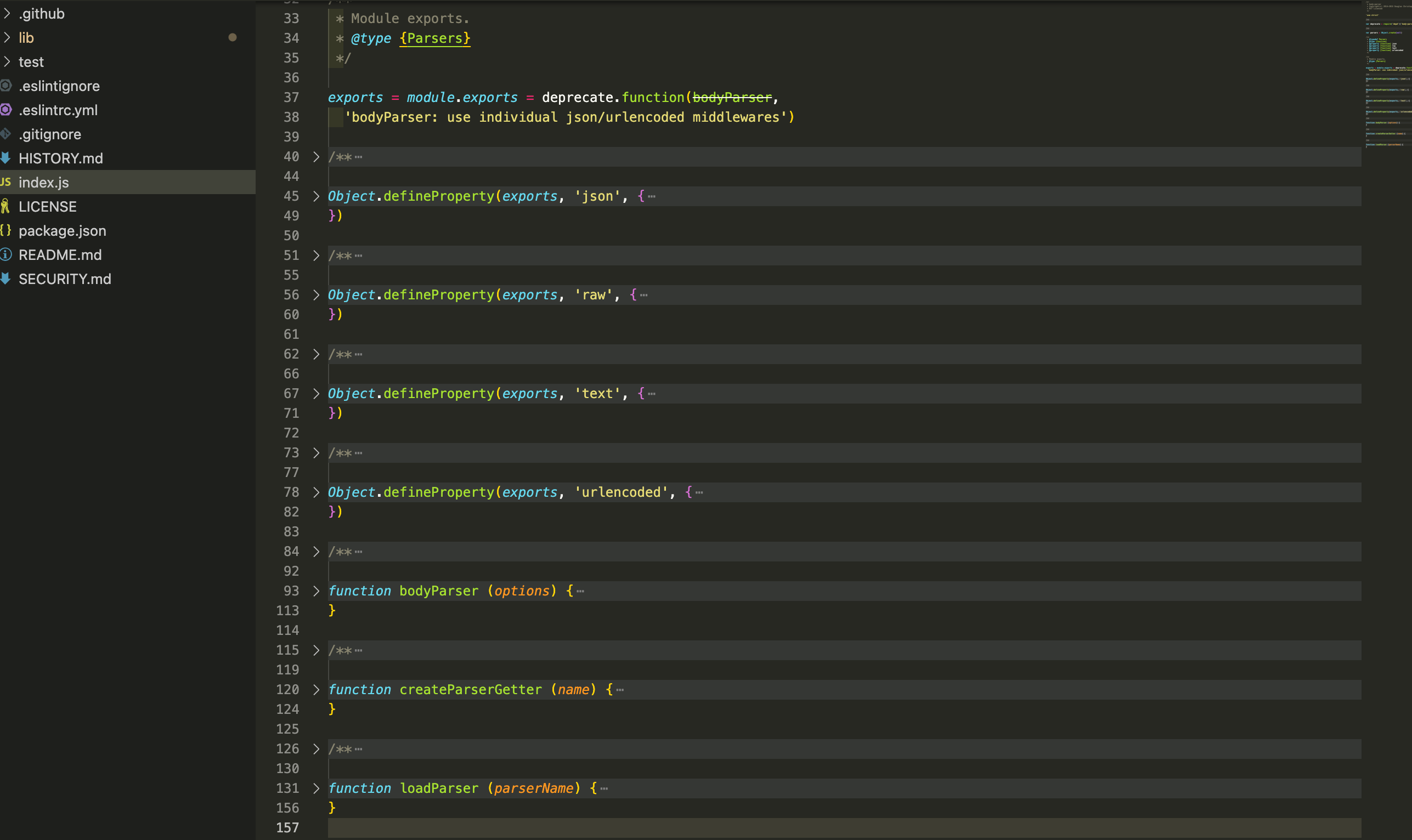
37行导出了一个函数 bodyParser,然后从47行开始使用 Object.defineProperty 定义了四个属性(json、raw、text、urlencoded),这些属性分别对应四种解析器
loadParser函数就是去引入这四种解析器,代码如下:
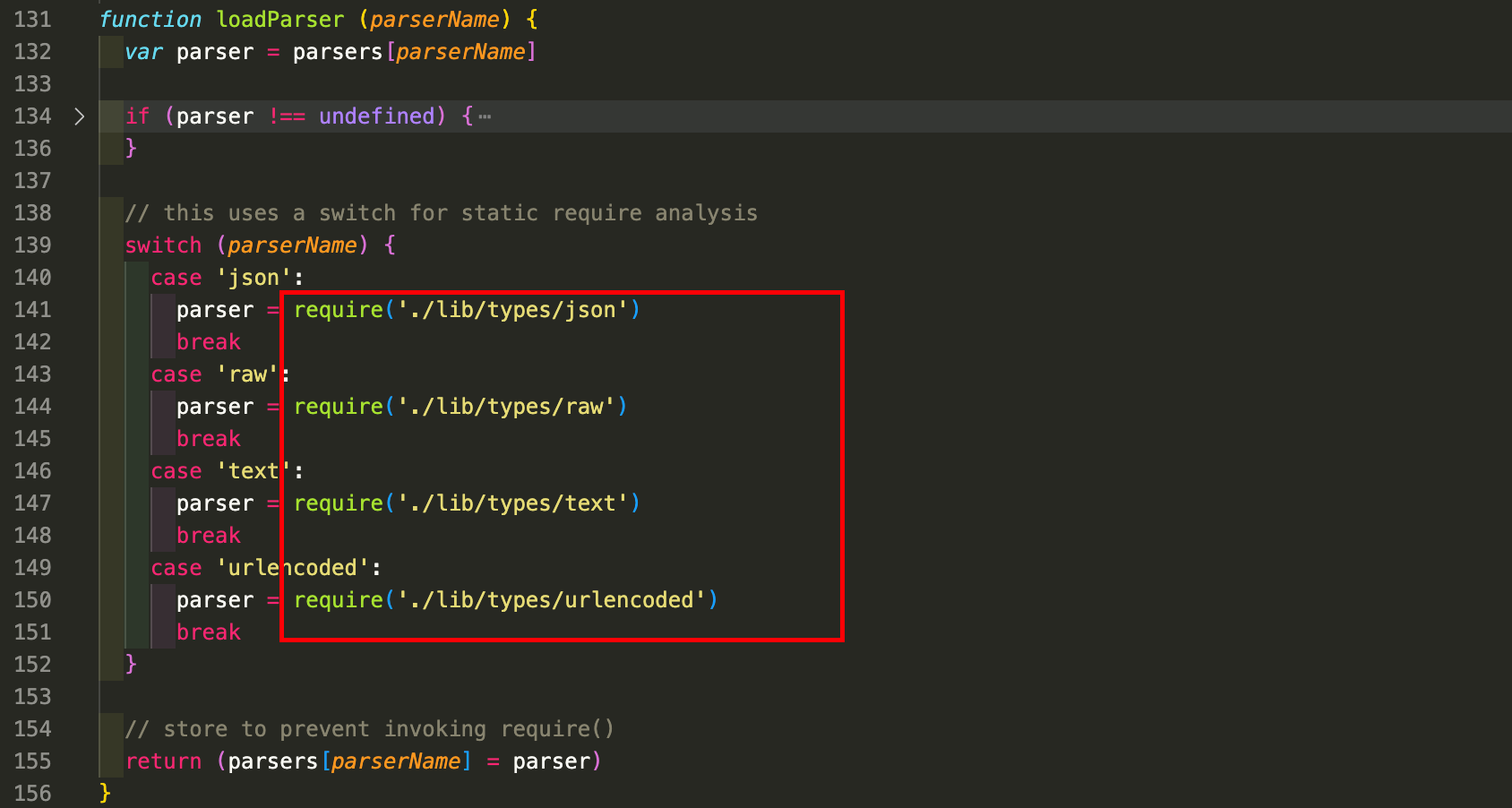
index.js内容比较简单,下面我们来看下json格式的请求体是如何解析的
json.js阅读
json.js 用于处理 JSON 请求主体的中间件,它会解析请求主体,验证内容类型和字符集,最后会吧结果存储在 req.body 中
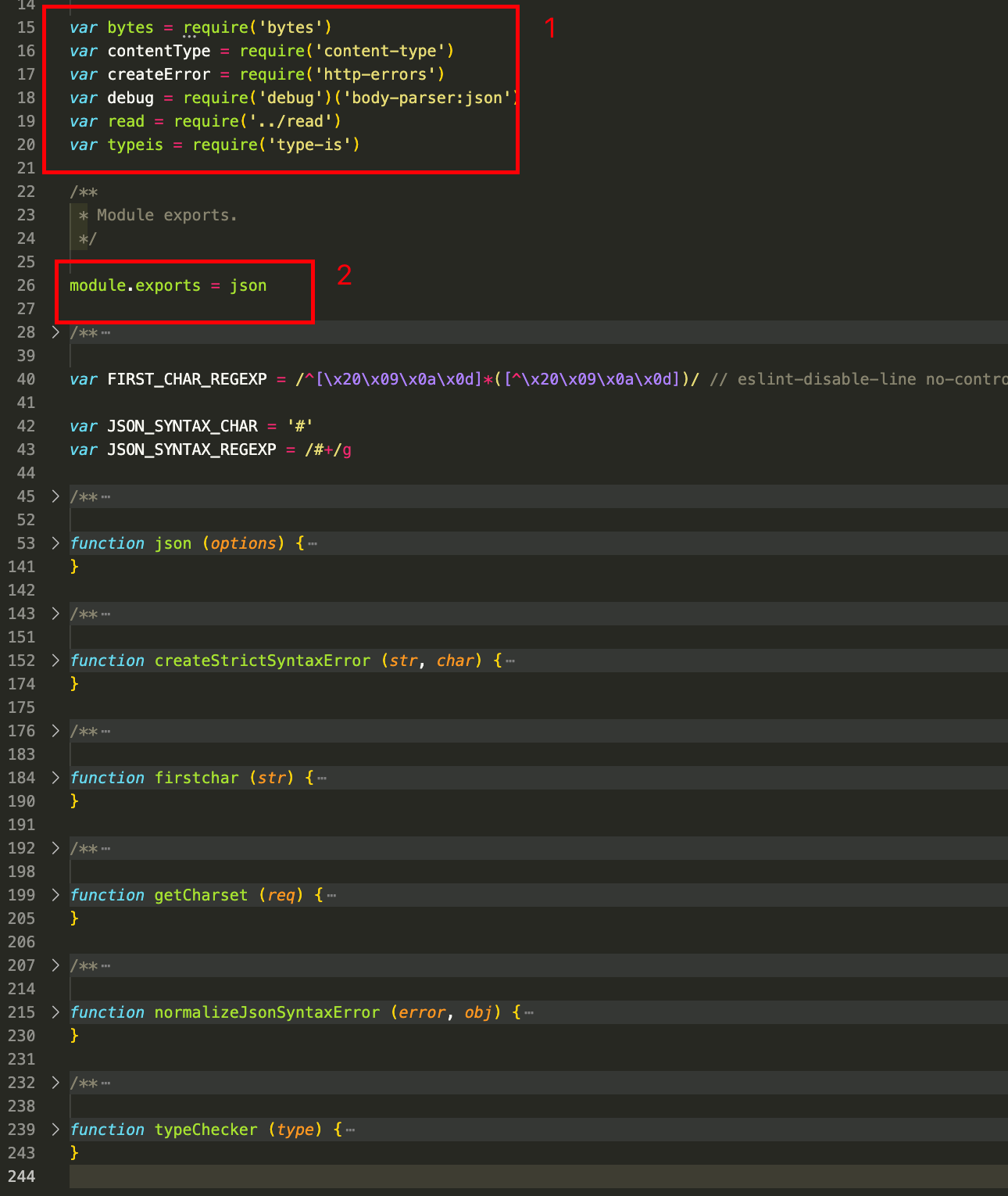
- 首先是导入所需的模块,比较关键的有:
content-type(用于处理请求的内容类型)、read(lib目录下读取请求主体的函数)。 - 26行导出了
json中间件函数,用于处理 JSON 请求主体。json中间件函数接受一个配置作为参数,重点的配置项如下:limit:限制请求主体的大小,默认为 “100kb”,超过limit的限制就会报错inflate:是否解压缩请求主体,默认为true。一般来说请求的主体内容都是经过压缩的,type:用于指定期望的请求主体内容类型,默认为 “application/json”。
重点是json函数,我们来看一下:
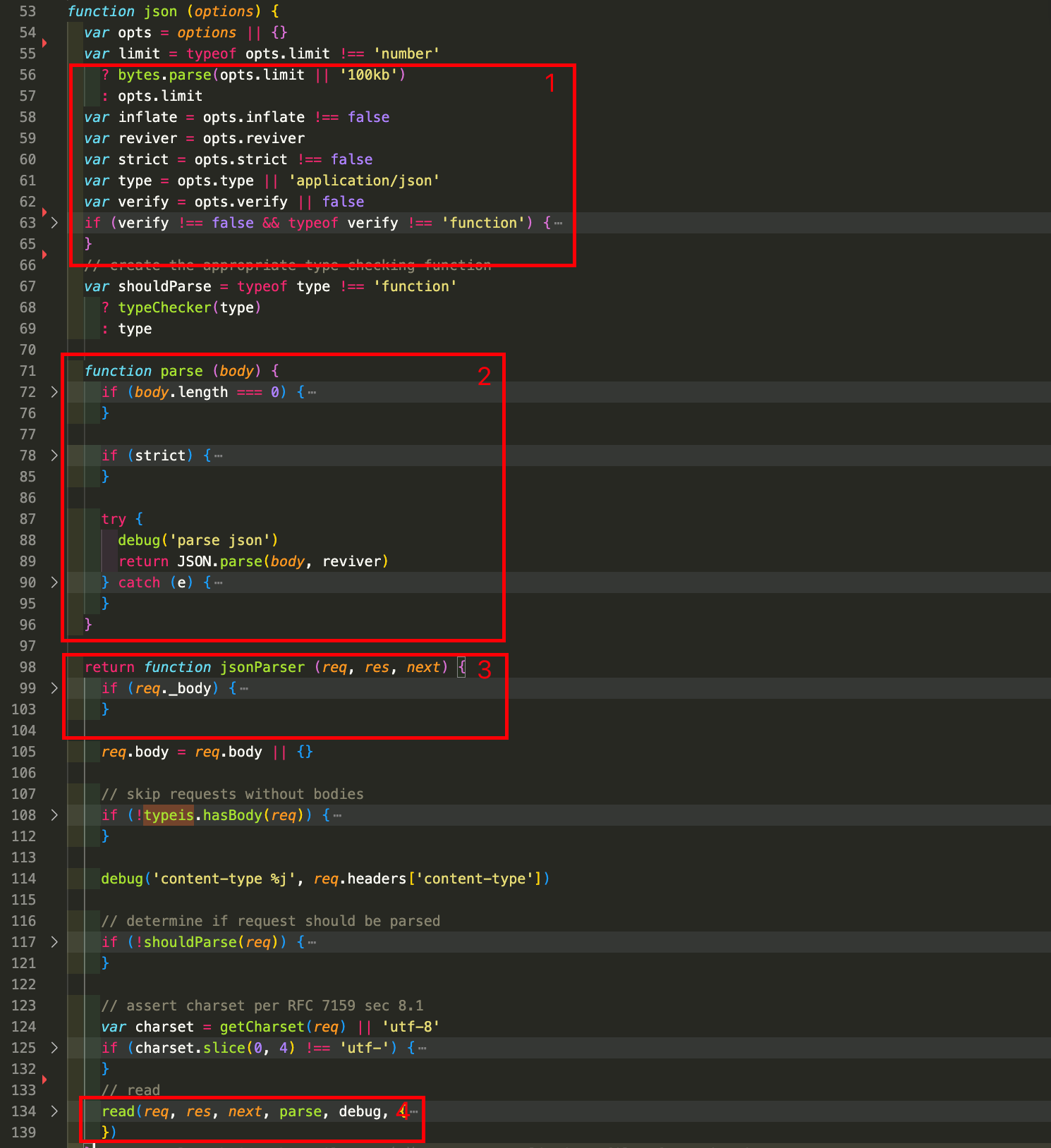
- 初始化一些配置项
- 第2部分是parse函数,核心代码是第89行,用
JSON.parse来解析body内容 - 98行会返回一个
jsonParser函数,然后通过req._body判断请求的主体是否已经解析过,jsonParser会调用第四部分的read函数来解析请求体
read.js主要内容如下:
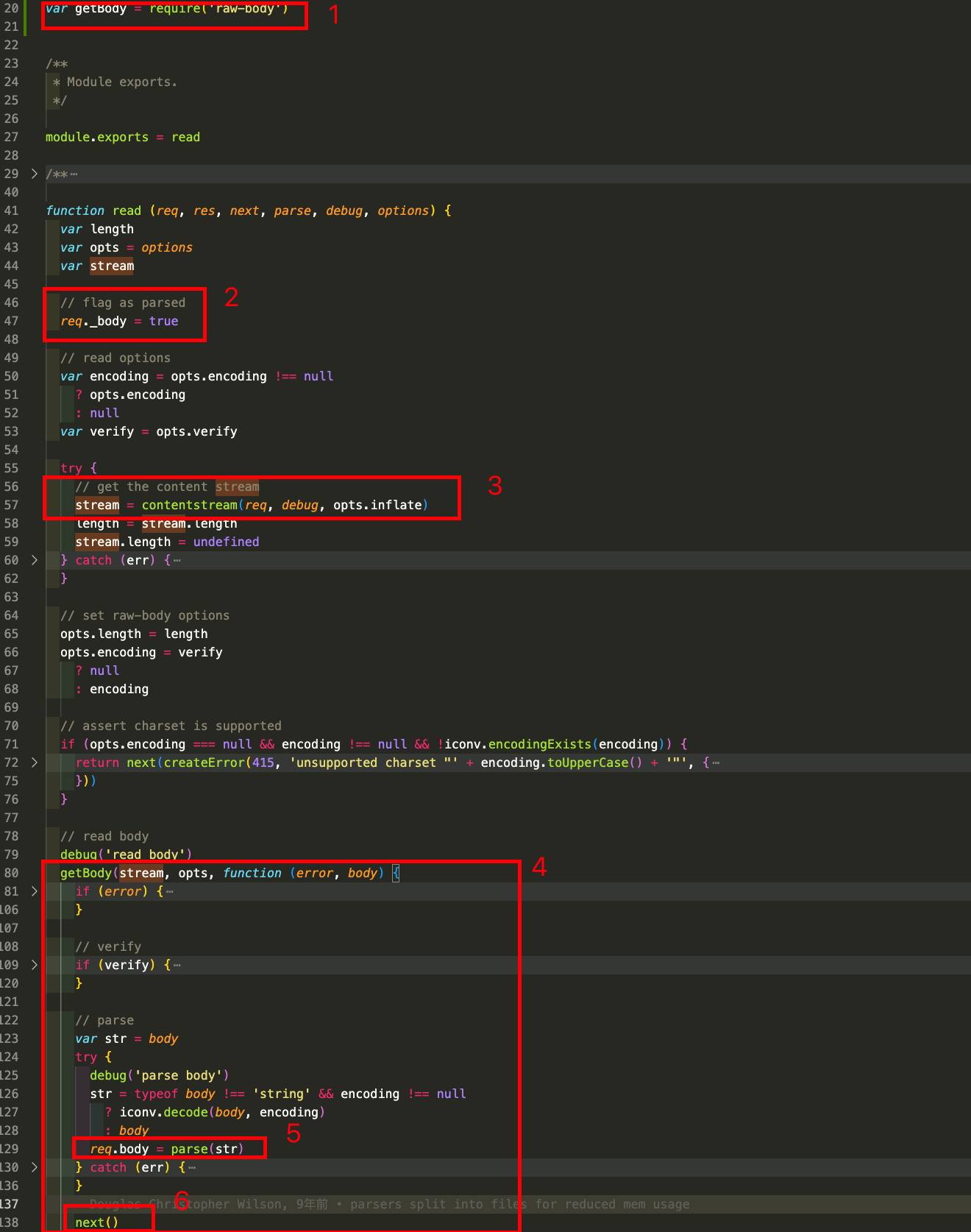
-
read.js引入了好几个模块。比较重要的是raw-body模块,
raw-body是一个用于处理请求主体的库。主要作用是从请求流中读取原始的请求主体数据,但是不进行解析或处理,方便用户自行处理请求主体数据 -
47行会吧
req._body标记为true,表示已经解析过请求体了,比如我们使用了两个中间件:app.use(bodyParser.json())app.use(bodyParser.urlencoded({ extended: false }))如果请求体被json中间件解析过,在经过urlencoded中间件时,不会再解析
-
调用
contenstream函数解压缩请求体,contenstream会根据请求体的编码进行解压缩,并返回解压缩之后stream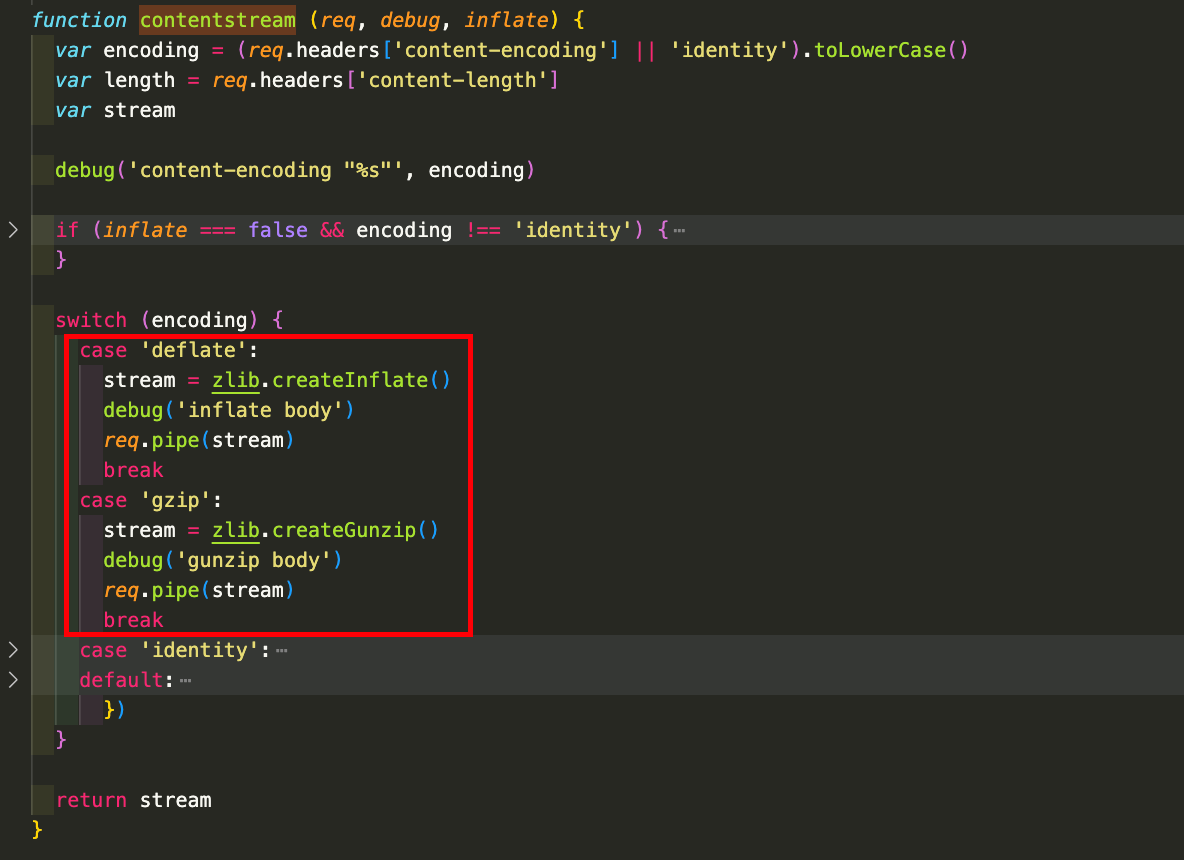
-
getbody就是从请求流中读取原始的请求主体数据,然后在回调函数的第二个参数返回内容
-
129行比较关键,会调用json.js里面传过来的parse函数进行解析,并吧结果存储在
req.body中。 -
最后,调用next函数吧控制权传递给下一个中间件。
urlencoded.js阅读
urlencoded.js文件和json.js大部分内容都比较类似,不同的地方是如何解析请求体,核心代码是urlencoded这个函数:
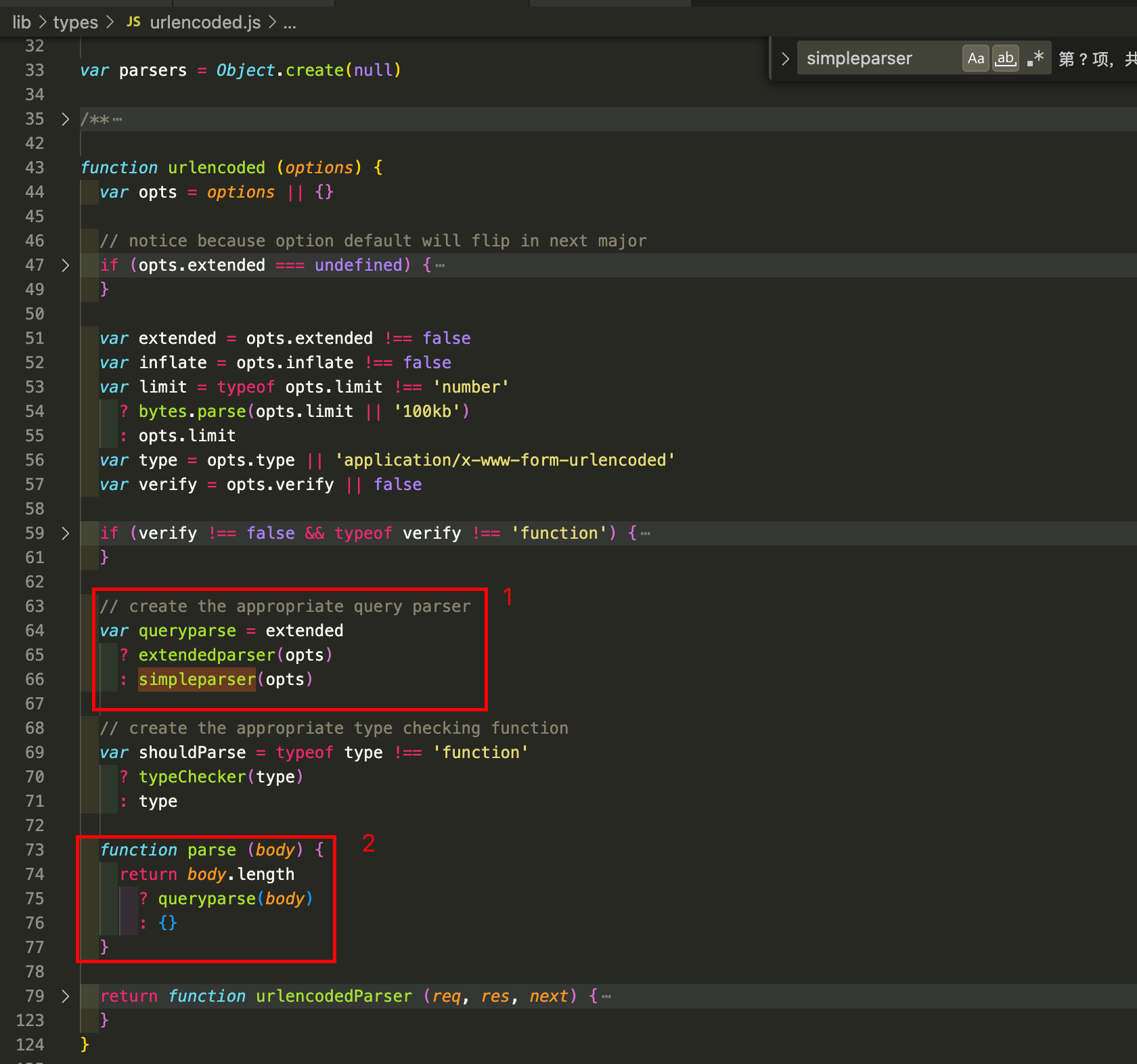
-
通过判断配置中的extended参数来判断使用那个解析器,
simpleparser内部使用的Nodejs内置的querystring模块,而extendedparser使用的是第三方的qs模块来解析,qs模块功能要更加强大一些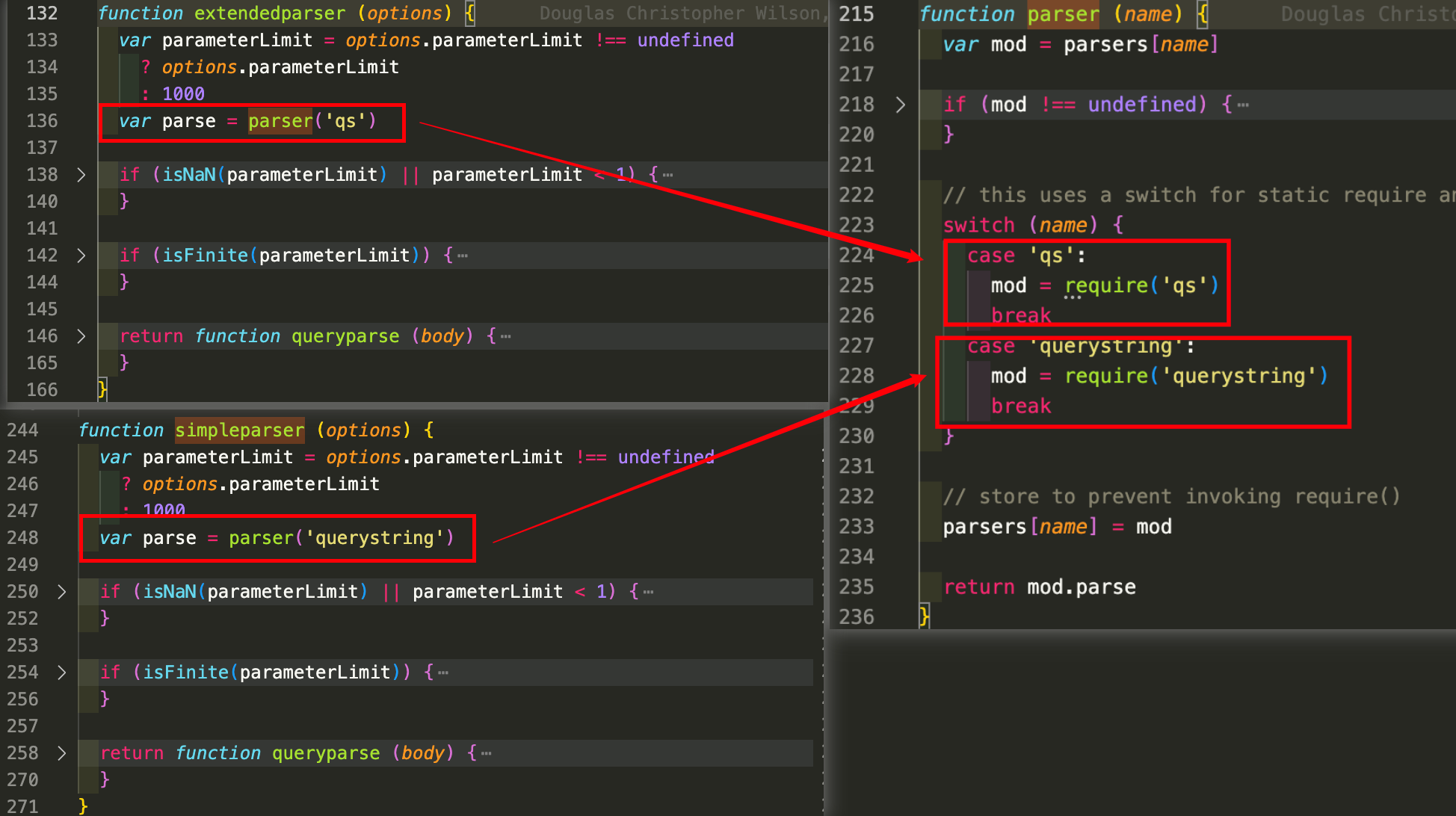
-
parse函数,内部调用queryparse函数去解析请求体
感兴趣的同学可以自行阅读raw.js和text.js代码,整体内容和上面内容差别不太大
完整代码在:
https://github.com/AC-greener/build-your-npm-package/tree/main/body-parser
总结
虽然我们也实现了json和urlencoded请求体的解析,但是代码还有很多不完善的地方,比如没有处理请求体过大的情况,缺乏错误处理,如果请求体格式不正确或者出现其他问题,不会提供足够的错误信息,而这也是我们在生产环境使用第三方模块的原因。
大伙可能疑问raw-body模块是如何处理请求体的,由于篇幅原因,我们不在这里展开讲了,下一篇我们会讲一下raw-body模块源码
觉得有收获的铁子帮忙点个赞~🙏