NodeJS Stream模块基础教程
为什么要使用流
Node.js是以事件为基础的,处理I/O操作最高效的方法就是实时处理,尽快地接收输入内容,并经过程序的处理尽快地输出结果。
你之前可能会写出这样的代码:
var http = require('http');var fs = require('fs');
var server = http.createServer(function (req, res) { fs.readFile('./data.txt', function (err, data) { res.end(data); });});server.listen(8000);这段代码会在每次请求时,将所有的源数据存放到缓存中,当整个数据源被读取完毕后,会将缓存中的数据立即传递给回调函数处理。如果data.txt文件非常大,比如说有几百MB甚至几百GB的大小。很明显,读取整个文件内容,然后从缓存中一次性返回的方式并不好。如果程序同时读取
很多这样的大文件,很容易导致内存溢出。除此之外,V8中的缓存区最大不能超过0x3FFFFFFF字节(略小于1GB)。
可以用下面这幅图来理解这个例子:
这里假设data.txt的内容为 Hello Node.js
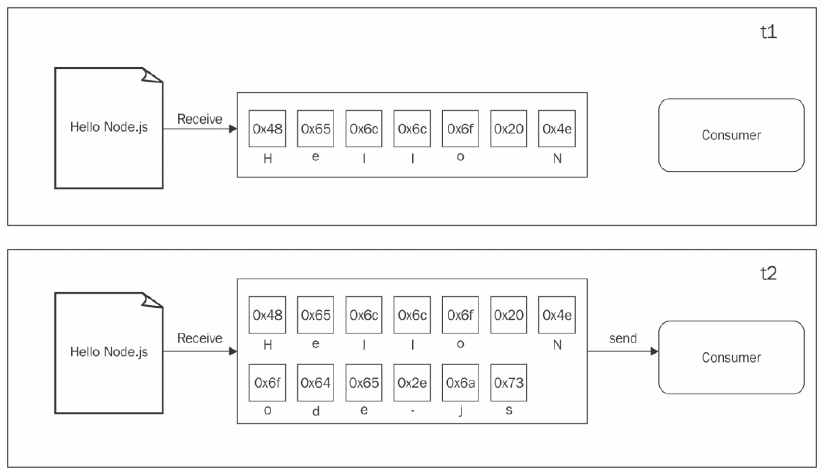
我们从data.txt中读取内容,可以看到在t1时刻,有些数据被读取到缓存中。但是直到在t2时刻,最后一个数据块也被接收,才完成了本次读取数据的过程并将整个缓存区的数据传输给处理程序。
不同的是,使用流就能尽可能快地处理接收到的数据。
代码如下:
var http = require('http');var fs = require('fs');
var server = http.createServer(function (req, res) { var stream = fs.createReadStream('./data.txt'); stream.pipe(res);});server.listen(8000);在这里,.pipe()方法会自动帮助我们监听data和end事件。上面的这段代码不仅简洁,而且data.txt文件中每一小段数据都将源源不断的发送到客户端。
可以用这张图来理解:
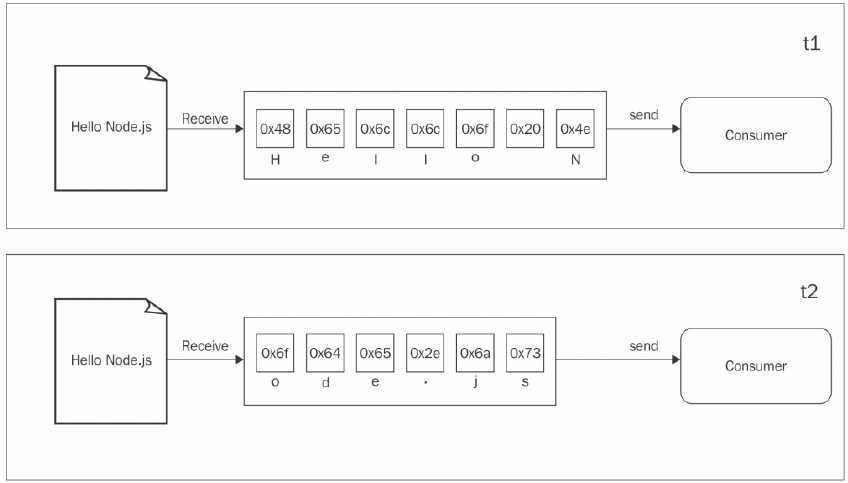
我们从数据源读取每一个数据块,然后立即提供给后续的处理流程,这时就可以立即处理读取到的数据而不需要等待所有的数据被先存放在缓存中。
可组合性
组合流主要使用pipe()这个方法。可以通过使用可读流的pipe()方法将一个可读流连接到另一个可写/双向流或转换流。

比如我们要从文件中读取内容然后进行压缩和加密,代码可以是这样的:
var http = require('http');var fs = require('fs');var zlib = require('zlib');var crypto = require('crypto');var server = http.createServer(function (req, res) { fs.createReadStream('./data.txt') .pipe(zlib.createGzip()) .pipe(crypto.createCipher('aes192', 'a_shared_secret')) .pipe(res)});server.listen(8000);在unix操作系统中,一般使用管道| 操作符来连接流,比如:
cat file.txt | grep "error" | wc -l
流的分类
Node.js中的每个流的实例都是stream模块提供的四个基本抽象类之一的实现:
- stream.Readable
- stream.Writable
- stream.Duplex
- stream.Transform
Readable可读流
一个可读流代表了一个数据源,在NodeJS中,可以使用stream模块提供的Readable抽象类来实现。

NodeJS中最常见的几个可读流是process.stdin、fs.createReadStream和HTTP服务器中的IncomingMessage对象。
从可读流中获取数据有两种模式:
非流动模式
从可读流中读取数据的默认方式都是添加一个对于readable事件的监听器,在读取新的数据时进行通知。然后,在一个循环中,读取所有的数据直到内部的缓存被清空。
下面是一个简单的程序,从标准输入(可读流)读取数据并将所有内容返回到标准输出:
#!/usr/bin/env nodeprocess.stdin .on("readable", () => { let chunk; console.log("New data available"); while ((chunk = process.stdin.read()) !== null) { console.log(`Chunk read: (${chunk.length}) "${chunk.toString()}"`); } }) .on("end", () => process.stdout.write("End of stream"));数据可以在readable的事件监听器中被读取到,该事件会在新数据可读时被触发。当内部缓存中没有更多的数据可读时,read()方法会返回null,这时,就必须等待readable事件再次被触发,告诉我们有新的数据可以读取或者等待end事件,告诉我们整个可读流已经结束了
可以在命令行这样使用app.js:
cat data.txt | ./app.js
data.txt内容为Hello Node.js
打印内容如下:
New data availableChunk read: (13) "Hello Node.js"New data availableEnd of stream流动模式
另一种从流中读取数据的方式是给data事件添加一个监听器,这就是流动模式的流读取,在该模式下数据并不是通过read()来拉取,相反,只要流中的数据可读,便会立即被推送到data事件的监听器,可以讲之前的代码改写成这样:
process.stdin .on("data", (chunk) => { console.log("New data available"); console.log(`Chunk read: (${chunk.length}) "${chunk.toString()}"`); }) .on("end", () => process.stdout.write("End of stream"));在上面的例子中,我们监听 data 事件来获取输入数据。当有数据输入时,chunk 参数会包含输入的数据。
实现可读流
接下来我们来实现一个新的可读流。需要创建一个新的类,继承stream.Readable的原型。具
体的流实例必须提供对于_read()方法的实现
以下是一个简单的Node.js可读流示例,实现一个生成字符串a-z的流。
const { Readable } = require('stream');
class AlphabetStream extends Readable { constructor(options) { super(options); this.alphabet = 'abcdefghijklmnopqrstuvwxyz'; this.index = 0; }
_read() { if (this.index < this.alphabet.length) { const letter = this.alphabet.charAt(this.index++); this.push(letter); } else { this.push(null); } }}
const alphabetStream = new AlphabetStream();
alphabetStream.on('data', (chunk) => { console.log(chunk.toString());});
alphabetStream.on('end', () => { console.log('Finished reading stream');});在命令行执行node index.js就能看到a-z被打印出来
Writable可写流
可写流表示数据的目的地,在Node.js中可以使用流模块提供的抽象类Writable来实现。

最常见的可写流是process.stdout和fs.createWriteStream ,console.log其实就是process.stdout的封装。
向流中写入数据
向可写流中写入数据只需要调用write()方法:
writable.write(chunk,[encoding],[callback])
如果不再将更多数据写入流中,需要使用end()方法:
writable.end([chunk],[encoding],[callback])
可以通过end()方法写入最后的数据块,这时的callback函数相当于为finish事件注册的监听器,当流中所有的数据被清空时,该函数会被执行。
下面我们创建一个简单的HTTP服务端,输出随机的字符串:
const http = require("http");
const server = http.createServer((req, res) => { res.writeHead(200, { "Content-Type": "text/plain" }); while (Math.random() < 0.95) { res.write(Math.random().toString() + "\n"); } res.end("\nThe end...\n"); res.on("finish", () => console.log("All data was sent"));});
server.listen(8080, () => console.log("Listening on http://localhost:8080"));该HTTP 服务端会向res 对象中写数据, 该对象是http.ServerResponse的实例,同时也是一个可写流。
首先设置了一个有5%的可能性被终结的循环,然后向流中写入随机的字符串。一旦循环结束,调用end()方法,同时,在结束之前写入最后的字符串。
最后,为finish事件注册监听器,当缓存中所有数据被清空时会被触发。
可以这样测试该模块:
node index.js
然后使用curl命令:curl localhost:8080
输出内容如下:
0.30690087451167770.30247070969909240.0134925208489828920.067198427089620870.65769516249129210.33857360073431875
The end...背压(Back-pressure)
和液体在真实的管道中流动一样,Node.js中的流也可能遇到瓶颈,即将数据写入流的速度比从流中读取的速度快。当越来越多的数据聚积到内部缓存中,会导致不必要的内存使用。
为了防止这种情况的发生,当内部缓存超过了highWaterMark(内部缓冲区已满时流应该暂停读取数据的最大字节数)的限制时,writable.write()会返回false,告诉应用应该停止写数据的操作。
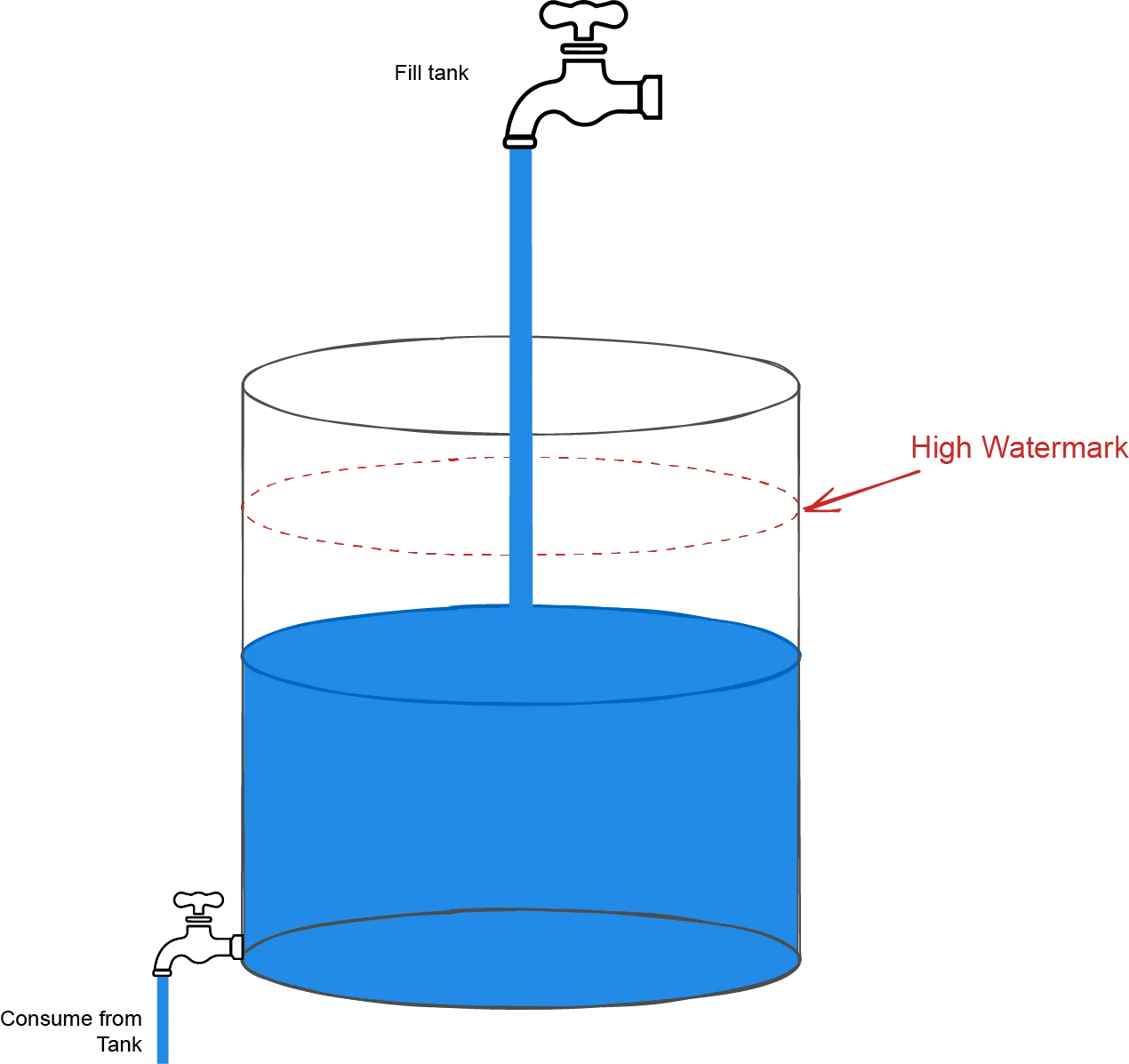
当缓存被清空后,drain事件会被触发,通知应用现在已经安全,可以重新执行写操作。这一机制也叫做背压(backpressure)。
下面是一个背压的例子:
const http = require("http");
const server = http.createServer((req, res) => { res.writeHead(200, { "Content-Type": "text/plain" }); function generateMore() { while (Math.random() < 0.95) { //为了提高发生背压的概率,将数据块的大小提高到15KB,和默认的highWaterMark非常接近。 let shouldContinue = res.write(generateRandomString(15 * 1024)); if (!shouldContinue) { console.log("Backpressure"); return res.once("drain", generateMore); } } res.end("\nThe end...\n", () => console.log("All data was sent")); } generateMore();});
server.listen(3002, () => console.log("Listening on http://localhost:3002"));
//生成一些字符串function generateRandomString(length) { const characters = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789"; let result = ""; for (let i = 0; i < length; i++) { result += characters.charAt(Math.floor(Math.random() * characters.length)); } return result;}我们使用generateRandomString来生成字符串,为了提高发生背压的概率,将数据块的大小提高到15KB,在向响应中写入一个数据块后,会检查res.write()的返回值,false表示内部缓存已经满了,应该停止发送更多的数据。这时,会跳出函数的执行,并在drain事件触发时开启写数据流程。
使用*curl来发送一个客户端请求,这时有很大的可能会遇到背压的情况:*
curl localhost:3002
输出如下:
BackpressureBackpressureBackpressureBackpressureBackpressureBackpressureBackpressure
All data was sent实现可写流
可以通过继承stream.Writable类和实现_write()方法来创建一个新的可写流。
首先创建一个接收以下格式对象的可写流:
{ path: <path to a file>,content: <string or buffer> }
对于每一个这样的对象,可写流都会将content部分的内容保存到path指定路径的文件中。
下面创建一个toFileStream.js模块:
const stream = require("stream");const fs = require("fs");const path = require("path");
class ToFileStream extends stream.Writable { constructor() { // 使用对象模式 super({ objectMode: true }); }
_write(chunk, encoding, callback) { //获取目录名 const dirName = path.dirname(chunk.path); // 创建目录 fs.mkdir(dirName, { recursive: true }, (err) => { if (err) { //在流操作发生错误,触发error事件时,可以将错误传递到回调函数 return callback(err); } // 可写流都会将content部分的内容保存到path指定路径的文件中。 fs.writeFile(chunk.path, chunk.content, callback); }); }}
module.exports = ToFileStream;新建一个模块测试我们刚创建的流:
const ToFileStream = require("./toFileStream.js");const tfs = new ToFileStream();tfs.write({ path: "file1.txt", content: "Hello" });tfs.write({ path: "file2.txt", content: "Node.js" });tfs.write({ path: "file3.txt", content: "Streams" });tfs.end(() => console.log("All files created"));运行这个test.js模块,就会看到当执行这段代码时会创建三个新的文件。
Duplex双向流(可读也可写)
双向流指的是既可以读取又可以写入的流。当我们需要描述一个既是数据源又是数据目的地的实体时,双向流就显得非常有用,比如Socket网络套接字。

双向流同时继承了stream.Readable和stream.Writable的方法。
我们既可以通过read()和write()方法读写数据,也可以同时监听readable和drain事件。
如果想要创建自定义的双向流,必须同时实现_read()和_write()方法。
下面的示例代码,创建了一个自定义的双工流 LogStream 来记录时间戳和处理数据块:
const { Duplex } = require('stream');
class LogStream extends Duplex { constructor(options) { super(options); this.readArr = []; // 每秒钟推送一个时间戳到内部缓冲区 setInterval(() => this.push(new Date().toString()), 1000); }
_read() { while (this.readArr.length) { const chunk = this.readArr.shift(); //将时间戳从内部缓冲区推送给可读端口 if (!this.push(chunk)) { break; } } }
_write(chunk, enc, cb) { console.log('write:', chunk.toString()); cb(); }}
const duplex = new LogStream();
duplex.on('readable', () => { let chunk; while ((chunk = duplex.read()) !== null) { console.log('read:', chunk.toString()); }});
duplex.write('Hello\n');duplex.write('World');duplex.end();
setTimeout(() => { // 结束流并关闭所有资源 duplex.destroy();}, 3000);我们创建了一个名为 LogStream 的自定义双工流,该流每秒钟记录一次当前时间戳并将其推送到可读端口。同时,当向可写端口写入数据时,它会将数据块记录到日志中。
创建了 LogStream 类的实例,并向其中写入两个数据块,然后结束了该流。在 3 秒之后,手动使用 destroy 方法关闭了流和所有资源。
Transform变换流
变换流是一种特殊的双向流,用来处理数据的转换。
它会对读取到的每一个数据块进行一些变换使其能被可读流读取。
最常见的是变换流是crypto stream ,用来对流进行一些加密

但如果想要实现一个新的变换流,则需要提供另一对方法:_transform()和_flush()。
_transform() 方法和 _flush()方法都是用于处理输入和输出数据的钩子函数,但它们被调用的时机不同:_transform()
方法在每次可读端读取数据时被调用,而 _flush()
方法仅在所有数据被处理完毕后执行一次。
下面是一个Transform变换流的例子:
const { Transform } = require('stream');
class UpperCaseTransform extends Transform { constructor(options) { super(options); this.prefix = options && options.prefix || ''; this.suffix = options && options.suffix || ''; this.buffer = ''; }
_transform(chunk, encoding, callback) { const upperChunk = chunk.toString().toUpperCase(); this.buffer += upperChunk; this.push(upperChunk); callback(); }
_flush(callback) { const transformed = this.prefix + this.buffer + this.suffix; this.push(transformed); callback(); }}
module.exports = UpperCaseTransform;这段代码实现了一个自定义的 UpperCaseTransform类,继承自 Transform类。将输入数据块转换为全大写格式,并在所有数据处理完成后添加前缀和后缀输出到可写端。
总结
本文介绍了Node.js中的流(Stream)概念,包括可读流(Readable)、可写流(Writable)、双向流(Duplex)和变换流(Transform)。流在Node.js中有着广泛的应用,比如读取、处理和写入大型文件、网络数据传输等。使用流可以提高代码的性能和可维护性,避免内存占用过多的情况,以及更好地处理异步任务。